StackOverflow Adventures: DocumentDb response chunking

Not long ago I stumbled upon this interesting question on stackoverflow:
The asker used the REST API of Azure DocumentDb to query some data, but they could only get back the first 100 documents. If they used the .NET SDK, they could get all the records. What's the problem?
I found the question intriguing. I have used DocumentDb in some of my projects, but I have always used the .NET SDK, never the REST API directly. So I dig into the documentation for the REST API, and it turned out that there might be a header in the response that showed if there could be more results:

I shared my hunch with the asker. Unfortunately I was late with my post, but finally it turned out that I was right. If you don't specify how many records you wish to get, you get back 100 (or there is also a quote for data size), and a continuation token, that you can use to query for the remaining data.
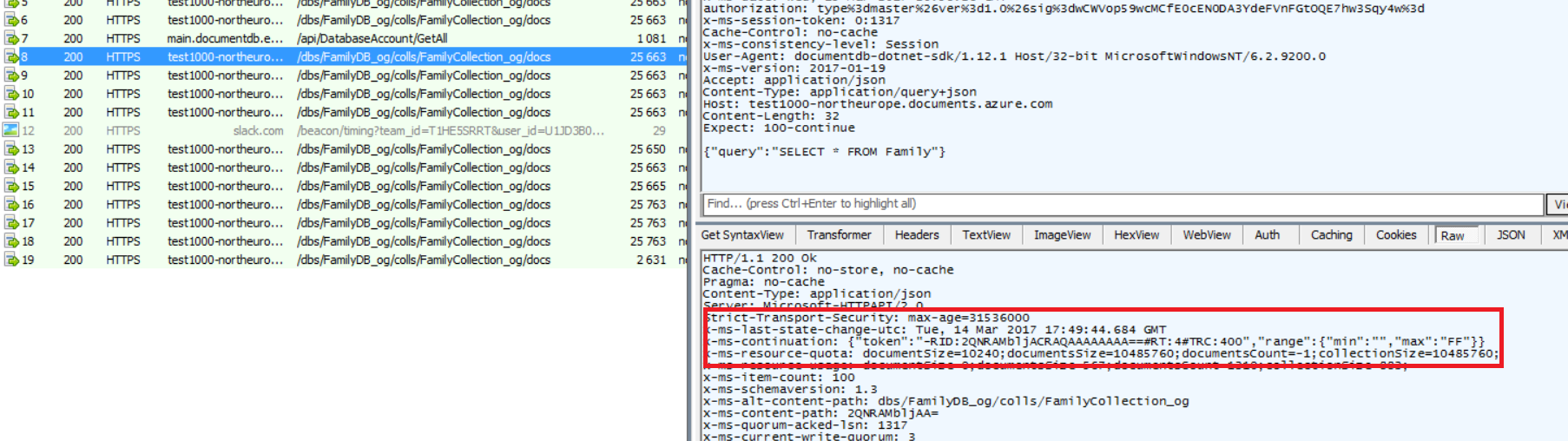
Just to check, I set up a simple collection using the Microsoft sample (sort of), and fired up Fiddler, to see what happens if I issue a query that returns more than 100 documents.
And sure enough, there was more than one request:
If you check out one arbitrary (not the last one, of course) request, you can see that there really is the continuation token specified in the response:
And then, in the next request (which issues the same query!) the same continuation token is specified:
So there. This is good to know :)