Azure Automation Job for Index Maintenance

Indices are good (yes, technically that is the plural form of index). They help you when you search for things - and that's mostly what databases are all about. But indices are only good if they are maintained.
When you do your inserts and deletes, indices can become fragmented. (If you don't know about fragmentation, check out this post:
https://www.mssqltips.com/sqlservertip/4331/sql-server-index-fragmentation-overview/)
But fortunately, you can defragment your indices quite easily, with one simple line:
ALTER INDEX ALL ON Mytable REBUILD with (ONLINE=ON)
This is all good, but doing this for every table is a pain. Even if you write something that queries all the tables and does some cursoring to do the actual rebuilding, you have to find a way to schedule and then monitor the script. Still a pain.
Thankfully, in the 21st century we have the cloud, and we have Azure. And you can easily set up an Automation runbook to do this for you. If you are not familiar with Azure Automation and want to be, check out the official documentation:
https://docs.microsoft.com/en-us/azure/automation/automation-intro
Setting up the runbook
Azure Automation is the best tool that you can use to set up an index rebuild maintenance job. It has a scheduler, it has built-in monitoring and logging, it is Powershell - all the goodies you might need. And the best is yet to come: there is a runbook gallery that you can choose prewritten runbooks from. The gallery contains ready-to-be-used scripts for common tasks, such as backup, scaling - and you have guessed it, for index maintenance.
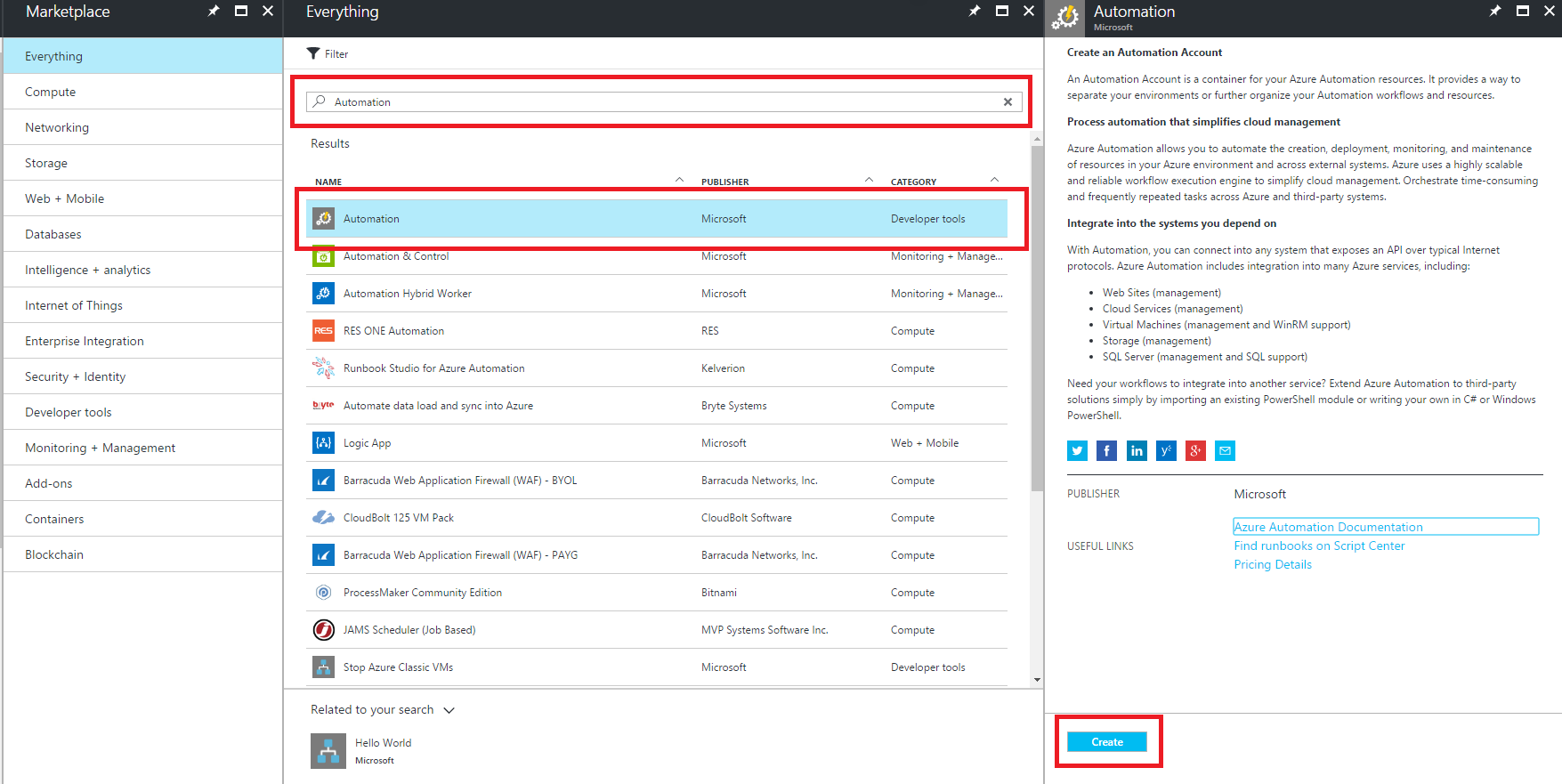
All you have to do is create an Automation Account:
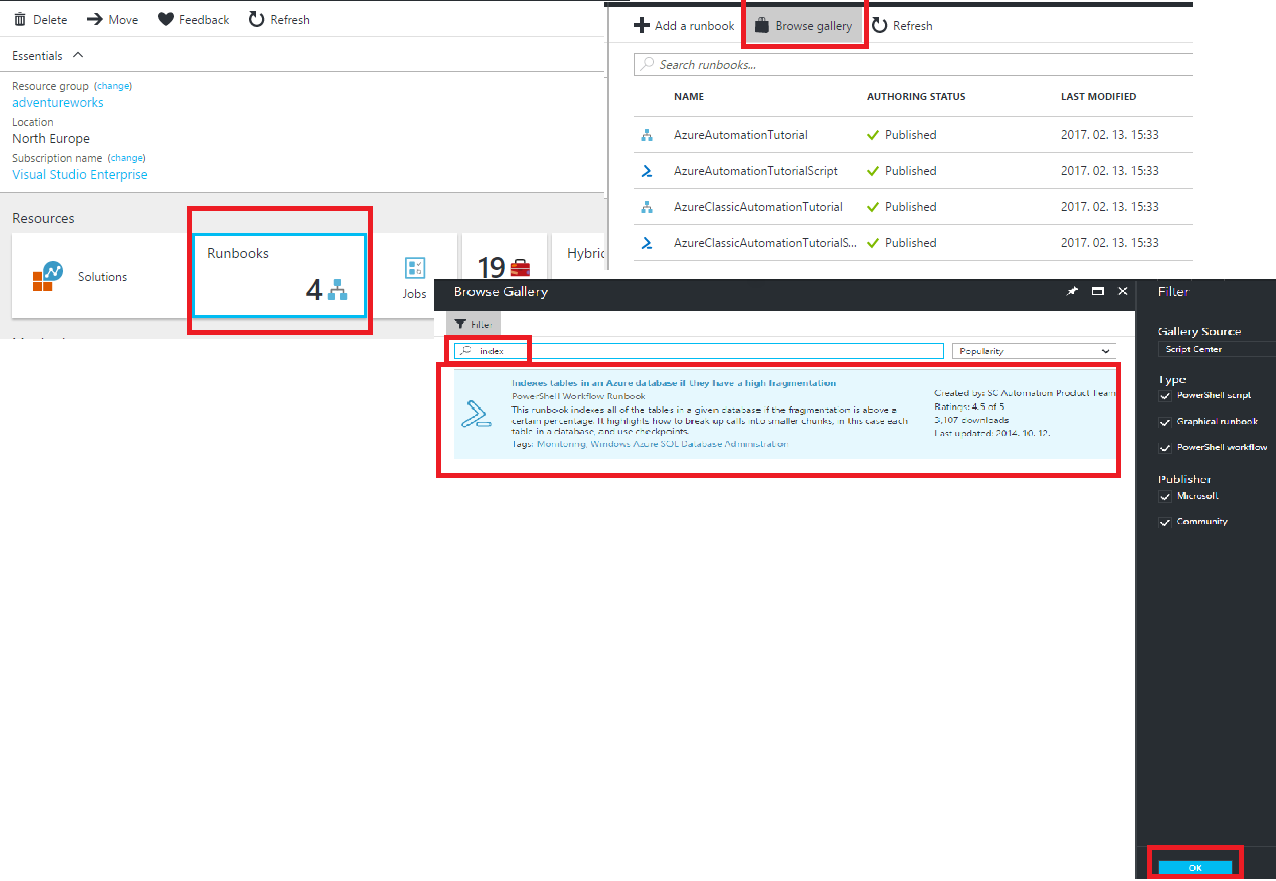
Then import the runbook:
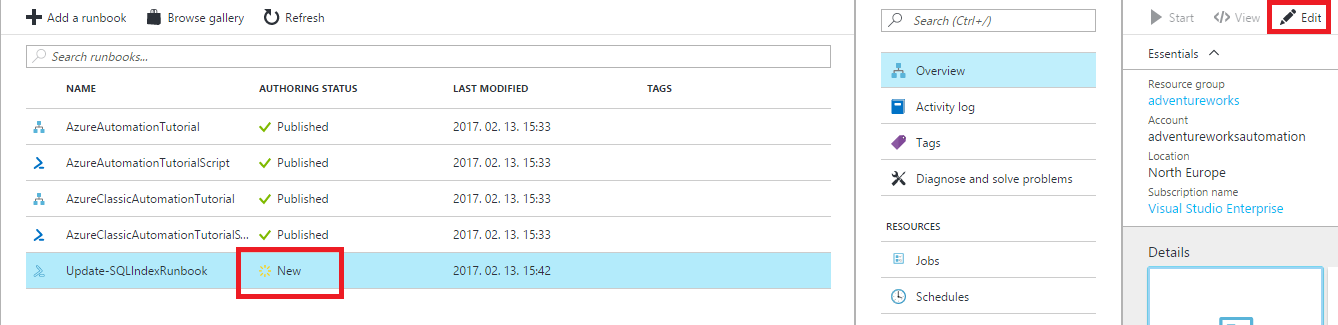
After the runbook is imported, you have to go into edit mode and press publish on the runbook, and it becomes active. In edit mode, you can also check out the source code of the runbook.
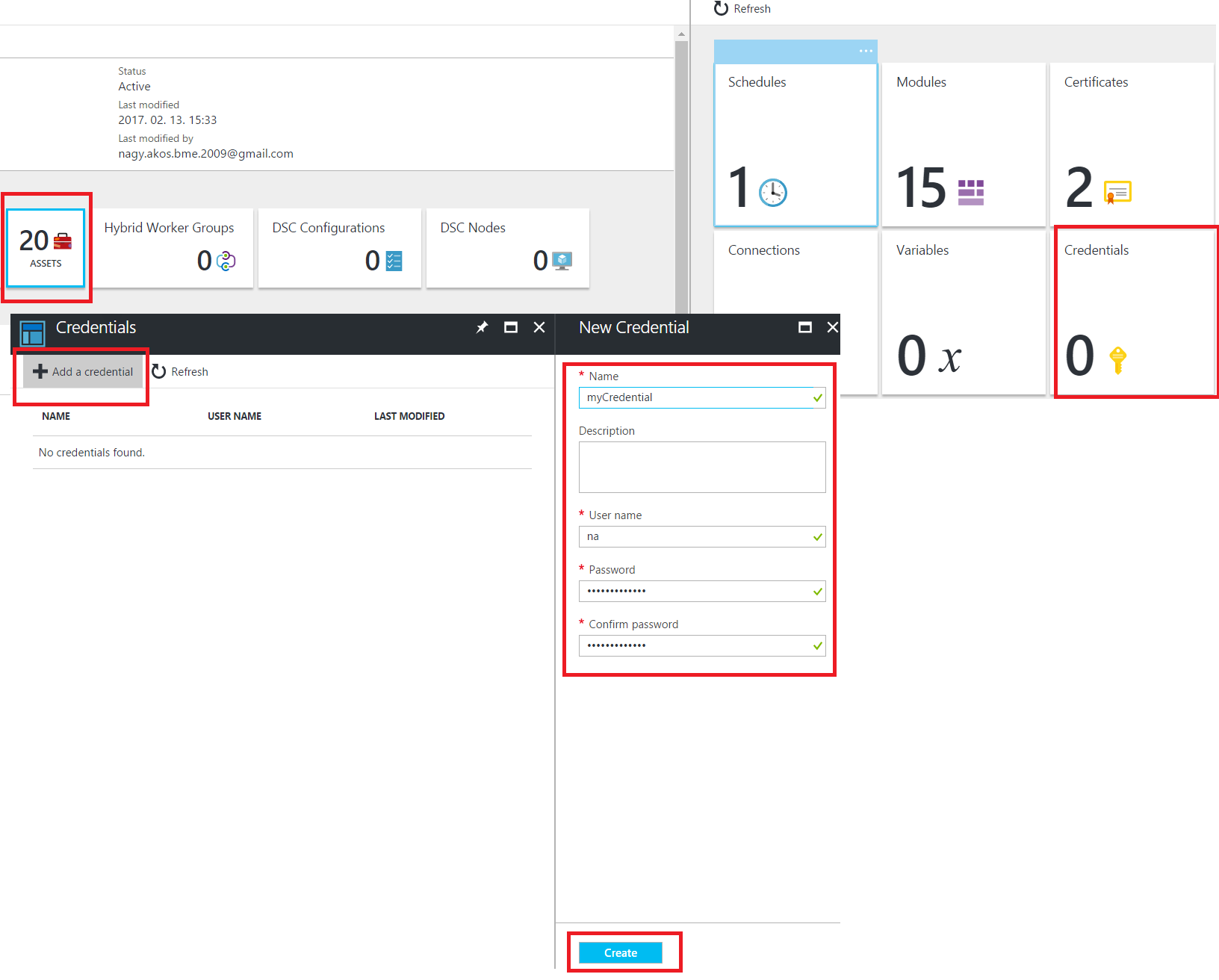
Then you have to add a credential to the runbook, which can be used to connect to the database (it's not as complicated as it seems, basically it is just a key-value pair, where the value is a username and a password, and the key can be used from the script to reference this particular credential). This has to be a user-password pair that can authenticate to the database, and the user should have rights to access database state and run the ALTER INDEX statement:
And finally schedule the runbook with the specified parameters. You can also test the runbook and start it immediately (but you have to specify the parameters in this case too):
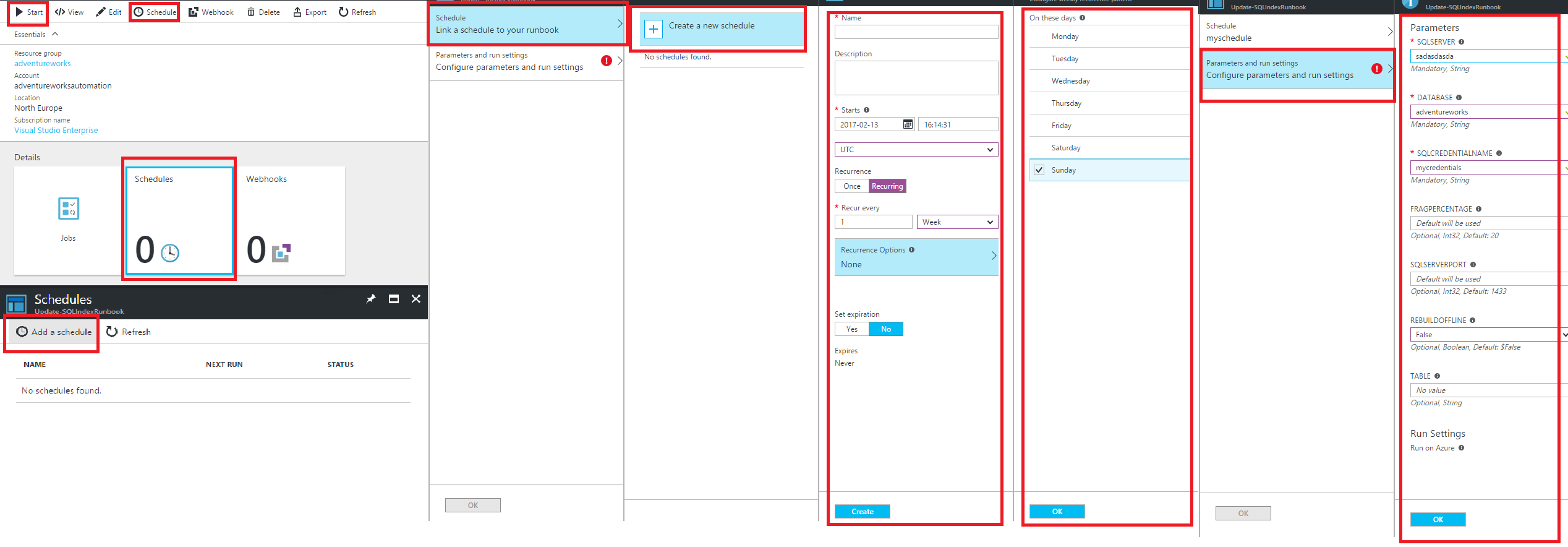
And there you have it.
But there is one catch...
Of course there is. Actually two. Or maybe even three.
First I tweaked the script a little bit and changed the lines
SELECT a.object_id, avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats (
DB_ID(N'$Database')
, OBJECT_ID(0)
, NULL
, NULL
, NULL) AS a
JOIN sys.indexes AS b
ON a.object_id = b.object_id AND a.index_id = b.index_id;
to
SELECT a.object_id, avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats (
DB_ID(N'$Database')
, OBJECT_ID(0)
, NULL
, NULL
, 'DETAILED') AS a
JOIN sys.indexes AS b
ON a.object_id = b.object_id AND a.index_id = b.index_id
If you look closely, you can see that I've changed the last parameter to 'DETAILED' from NULL. Well, this last parameter is responsible for the level of scanning the query actually does on an index to determine fragmentation. Checking the whole index might not be that cost efficient, so the function does a sampling of the index and calculates the fragmentation based on this (that's why the corresponding field is called avg_fragmentation_in_percent, note avg in the name). If the last parameter is NULL, then a LIMITED mode is used. If the last parameter is 'DETAILED', then the DETAILED mode is used. It takes a bit longer to calculate the fragmentation, but gives a much clearer picture of the index.
I also changed this:
SELECT t.name AS TableName, t.OBJECT_ID FROM sys.tables t
to this:
SELECT '['+SCHEMA_NAME(t.schema_id)+'].['+t.name+']' AS TableName, t.OBJECT_ID FROM sys.tables t
This is the part that's supposed to query the actual names of the tables (the query above simply returns object id-s). But the original version cannot handle tables that are not in the default schema. Oops.
But we're still not there yet: if you have special characters in your password connection string-wise (so things that have special meaning in the connection string, like ';' or '='), then this will fail. So you could go ahead and use the special escaping mechanisms, which might be a pain, especially since you have to do different escaping for different characters. To overcome this, you should use the SqlConnectionStringBuilder class. Probably the script would also be better off using it, so I've changed the connection string handling and now you can specify passwords or usernames that have ';' or ',' or '=' in them without a problem.
$connStringBuilder = New-Object System.Data.SqlClient.SqlConnectionStringBuilder
$connStringBuilder["Server"] = "tcp:$using:SqlServer,$using:SqlServerPort"
$connStringBuilder["Database" ] = "$using:Database"
$connStringBuilder["User ID"] = "$using:SqlUsername"
$connStringBuilder["Password"] = "$using:SqlPass"
$connStringBuilder["Trusted_Connection"] = $False
$connStringBuilder["Encrypt"] = $True
$connStringBuilder["Connection Timeout"] = "30"
$connString = $connStringBuilder.ConnectionString
$Conn = New-Object System.Data.SqlClient.SqlConnection($connString)
And now we are done :)
I uploaded the final script to GitHub.